Un site internet a toujours été visible dans Google, au sens propre du terme, grâce à 3 choses :
– son positionnement naturel
– la fiche Google Adresses
– les liens sponsorisés Google Adwords
« Mais ça, c’était avant ! »
De plus en plus de sémantique sur le Web
On a souvent parlé de « Web 3.0 » en le définissant comme un Internet plus intelligent, accessible, et universel.
Plusieurs hypothèses avaient été évoquées pour définir le futur et les évolutions du Web 2.0, comme la réalité augmentée ou encore le commerce ubiquitaire, pour fournir davantage d’informations aux internautes quelque soit leurs supports.
La plupart de ces prédictions se sont plus ou moins réalisées avec la généralisation des QRcodes, la multiplication des appli web comme Goggles par exemple, les nouvelles applications du RFID, ou encore l’actuelle mise en place du NFC.
Mais concernant le web de tous les jours, c’est davantage l’aspect sémantique qui a pris de l’importance avec le temps. L’organisation des informations et la structure des contenus est aujourd’hui au coeur du débat avec la mise en place progressive des normes HTML5 et les améliorations apportées par Google.
Évolution dans la structure de l’information
Le HTML 5
En proposant une nouvelle forme de structure de code, le HTML5 multiplie les possibilités.
Pour rappel, ce qui différencie principalement le HTML5 des versions précédentes, c’est la création de nouvelles balises sémantiques. En effet, au lieu d’avoir une page organisée avec <head> et <body>, le HTML5 introduit des balises comme <header>, <article>, ou encore <footer> pour indiquer aux robots d’indexation & aux moteurs de recherche quelle est la typologie de contenu. La balise <header> permettra par exemple de définir le header de votre page ou section de votre site.
On retrouvera également différents attributs sympa comme « draggable » pour utiliser le glisser-déposer directement sur la page web.
Les principaux avantages de cette version du HTML sont :
- Structurer l’information d’une façon plus claire
- Faciliter l’accessibilité du contenu via différentes techniques & supports
- Éliminer les soucis d’interopérabilité et compatibilité avec les anciens navigateurs et les plateformes propriétaires comme Flash par exemple.
Les Rich Snippets
Les « rich snippets » ou « extraits de données enrichies » en français, sont des données (ou plutôt microdonnées) issues du site web pour :
Le rich snippet rel="author" est aujourd’hui de plus en plus utilisé par les blogueurs, car elle permet de :
- Identifier le créateur du contenu (programme de paternité Google)
- Relier vos articles directement à votre compte Google+
- Augmenter le niveau de confiance du contenu
- Améliorer la visibilité de votre article/blog dans les résultats de recherche
C’est ce dernier point qui est vraiment intéressant. Dans l’exemple ci-dessous, votre positionnement n’est finalement plus déterminant dans les résultats, car un blog qui utilise les rich snippets et la balise author de Google est bien plus attrayant visuellement que le premier résultat.
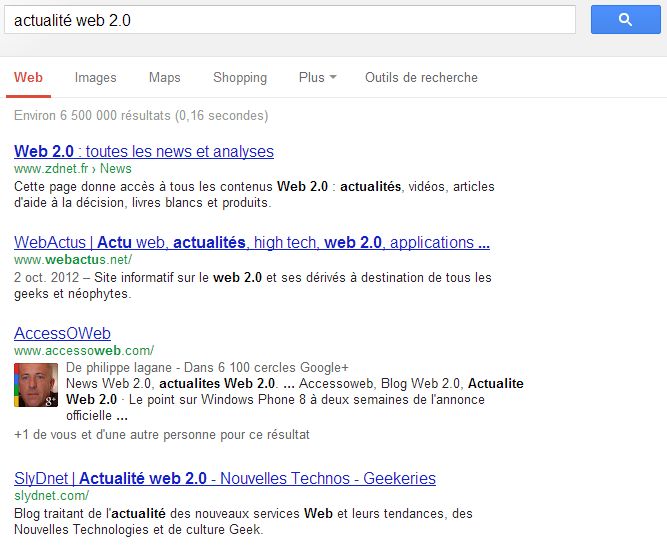
Un autre exemple avec une recherche concernant une recette de cuisine : le site attire tout de suite l’oeil de l’internaute grâce aux rich snippets.
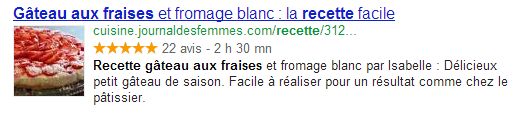
L’application de ce système de microdonnées/microformats à un site e-commerce est donc recommandé afin de se démarquer de ses concurrents.
L’arrivée de Google Knowlegde Graph
Qu’est ce que le Knowledge Graph ?
Google a dévoilé récemment sa dernière innovation concernant les résultats de recherche : le « Knowledge Graph » (« Graph du Savoir » en français). Concrètement, c’est un encart supplémentaire qui vient s’ajouter à droite des résultats naturels permettant d’obtenir en un coup d’oeil les principales informations sur une personne, un film, une entreprise, ou une zone géographique.
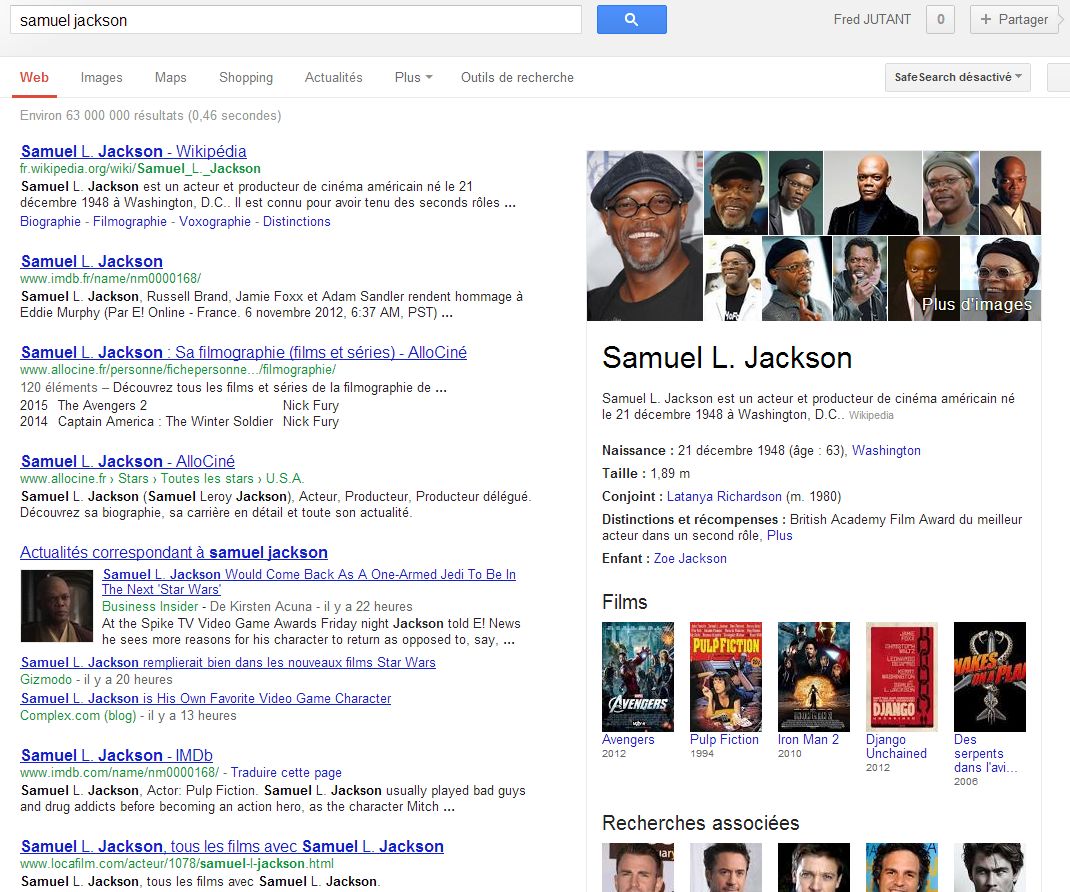
La mise en valeur des données sémantiques
Avec cette nouvelle fonctionnalité, Google fait un pas de plus vers le web sémantique. Si pour le moment le Knowlegde Graph récupère les données de Wikipédia, de Google Images, Google Maps, et plus généralement d’une base de données de plus de 500 millions d’entités, uniquement pour certaines expressions ; on pourrait très bien imaginer la prise en compte de l’ensemble des données sémantiques pour toutes les recherches dans un avenir à court ou moyen terme.
Le contenu : un élément central
L’élément qui reste le plus important aujourd’hui pour un blog, un site vitrine, ou une boutique en ligne, est de fournir un contenu intéressant, écrit pour les internautes et non uniquement dans un objectif de référencement et d’optimisation pour les moteurs de recherche.
Même si énormément d’actions de netlinking sont nécessaires derrière pour bien positionner un site Internet sur une thématique concurrentielle, le contenu reste la base de tout.
Pour conclure cet article sur les évolutions du web 2.0 et la mise en place progressive de la sémantique, je dirais que la notion de visibilité est en train d’évoluer. Peut-être que demain être premier sur ses mots-clés ne suffira plus pour être visible au sens propre du terme. Personnellement, je pense qu’il faudra suivre de près toutes ces histoires de sémantique et peut-être se tourner vers d’autres leviers en complément du référencement.
Qu’en pensez-vous ? Comment voyez-vous ces évolutions ?
Pour une fois je trouve que le knowledge graph est un bon ajout, il permet d’avoir tout de suite pas mal d’autres infos sur la chose recherchée et ce tout de suite sur la page de recherche, cela peut être un gain de temps dans certains cas. D’ailleurs Bing fait de même aussi, mais c’est moins réussi parait-il.
Par contre HTML5 et les rich snippets sont de bonnes choses pour renseigner les internautes, les robots et nettoyer un peu le web. 😉
Les entites nommées et compagnie, c’est encore beaucoup de storytelling !
Par contre le HTML5 et les rich snippets sont une bonne évolution !
Je ne parle pas d’afficher la vignette de l’auteur dans les SERP, mais du concept d’auteur en lui-même et donc de l’AuthoredRank.
J’en parle dans mon dernier podcast avec Sylvain Peyronnet, docteur en algorithme http://www.laurentbourrelly.com/blog/1288.php